昨天,我們把bagging算法算完,那今天,我打算建立分類函數:
在建立分類節點之前,得先把文字訊號轉成數字,可利用特徵工程中的label encoding或one hot encoding把文字訊息轉化成數字,有了數值之後就可以劃分節點
把特定特徵資料數值由小排到大後,再把前後相加的平均當成是節點
EX:資料為: [0.01,0.05,0.07,0.85,0.9]
那第一個節點就是(0.01+0.05)/2-->0.03
那第二個節點就是(0.05+0.07)/2-->0.06
…
最後一個節點就是(0.85+0.9)/2-->0.875
在依據之前說過的基尼係數就可以找出最佳的節點(而基尼係數要越小越好)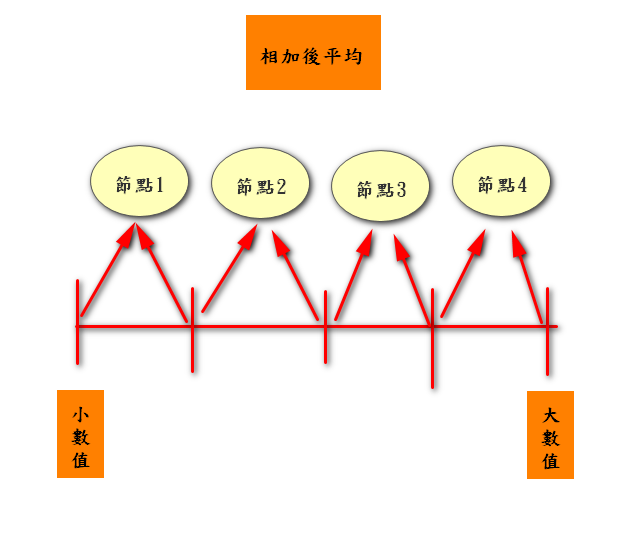
所以程式碼如下:
import random as rd
import numpy as np
#一個5維資料,共5筆,data(第0維為y)
data=[[1,1.01,0.852,5,1.5],[2,2.01,0.31,8,8.1],[1,3.01,0.589,9,5.6],[1,3.01,0.01,8,2.3],[2,4.01,0.258,10,1.1]]
#劃分方式
def split_Data_Set(data, index, value):
data1, data2 = [], []
for j in data:
#是否超過指定value
if j[index] <= value:
data1.append(j)
else:
data2.append(j)
return data1, data2
def Best_Feature(data):
#1為最大(效果最差)
best_Gini_cofe = 1
#位置最小為0,先設定-1
best_feature_col = -1
#因為數值有可能正或負,所以先設定None
best_split_value = None
#第i個特徵
for i in range(1,len(data[0]) - 1):
print("第",i,"個特徵")
feat_list = [k[i] for k in data]
sortfeats = sorted(list(set(feat_list)))
print("排序好特徵資料:",sortfeats)
split_list = []
for j in range(len(sortfeats) - 1):
split_list.append(np.round((sortfeats[j] + sortfeats[j + 1]) / 2,5))
print("節點:",split_list)
#每個劃分點都測試
for split_value in split_list:
subdata1, subdata2 = split_Data_Set(data, i, split_value)
#使用前幾天的Gini_cofe函數
new_Gini = Gini_cofe(subdata1, subdata2)
#如果基尼係數較小代表比較好
if new_Gini < best_Gini_cofe:
best_Gini_cofe = new_Gini
best_feature_col = i
best_split_value = split_value
return best_feature_col, best_split_value
best_feature_col, best_split_value=Best_Feature(data)
print("最佳分割特徵為: 第",best_feature_col,"特徵")
print("最佳分割特徵數值為:",best_split_value)
而結果如圖:
第 1 個特徵
排序好特徵資料: [1.01, 2.01, 3.01, 4.01]
節點: [1.51, 2.51, 3.51]
第 2 個特徵
排序好特徵資料: [0.01, 0.258, 0.31, 0.589, 0.852]
節點: [0.134, 0.284, 0.4495, 0.7205]
第 3 個特徵
排序好特徵資料: [5, 8, 9, 10]
節點: [6.5, 8.5, 9.5]
最佳分割特徵為: 第 2 特徵
最佳分割特徵數值為: 0.4495
所以最佳分割數據方式:是用第二個特徵數值為0.4495
把data分割成兩塊
好,今天實作部分就到這,明天再開始做建立決策樹的動作
此時男孩已走到森林前面,在入口處,有一個告示牌,上面寫著:小心有人?,男孩歪著頭想了一下,他以為是禁止進入意思,正在猶豫之際時,從森林深處傳來了一陣歌聲,那歌聲美妙至極,那旋律吸引著男孩,於是男孩頭也不回的,往森林裡走去
--|傾聽你的心跳,照著你的感覺走|-- MS.CM

